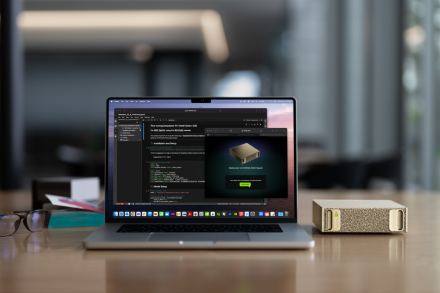

NVIDIA DGX Spark
DGX™ パーソナルAIコンピューター、AIの構築と実行を目的として設計
現在開催中のキャンペーン:
3rdロット完売、4thロット手配済み ! 「NVIDIA DGX Spark新春特別キャンペーン」
デスクトップ AI コンピューティングの必要性
生成 AI モデルの規模と複雑さの増大により、ローカルシステムでの開発作業は困難を極めています。大規模モデルのローカルでのプロトタイピング、チューニング、推論には、大量のメモリと高度なコンピューティング性能が必要です。企業、ソフトウェアプロバイダー、政府機関、スタートアップ企業、そして研究者が AI 開発に注力するにつれ、AIコ ンピューティングリソースの必要性は高まり続けています。
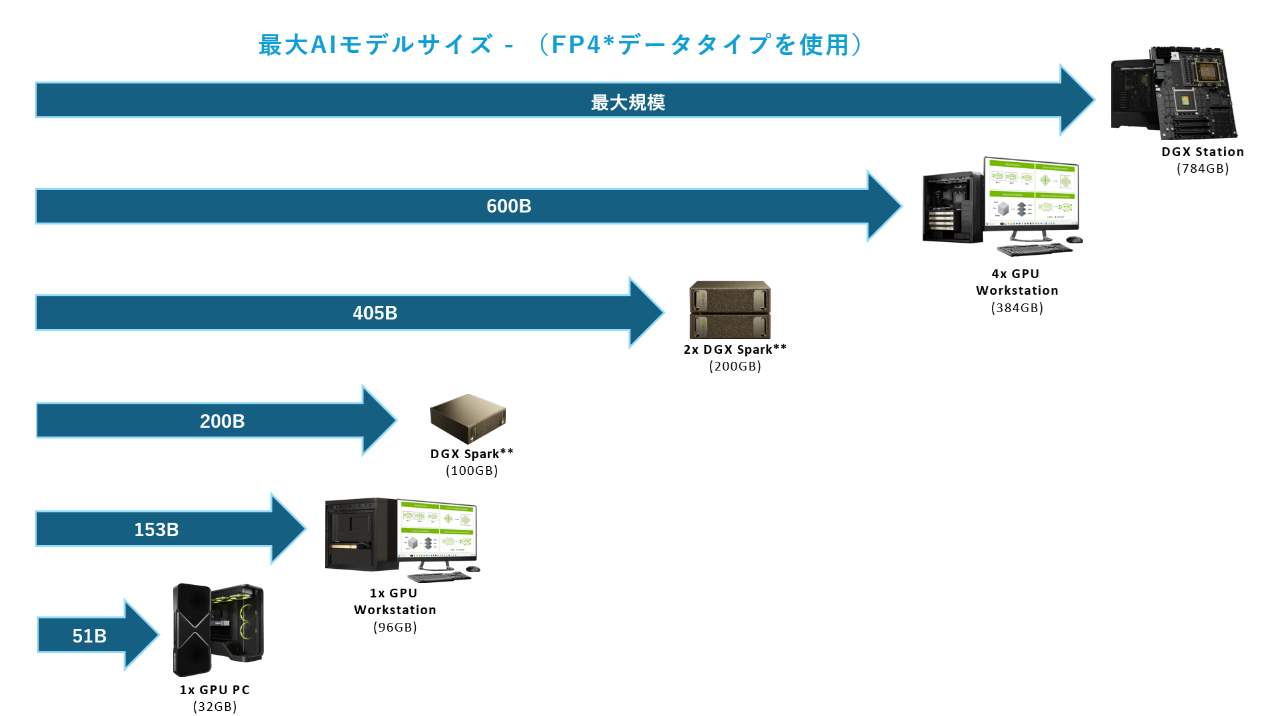
デスク上の 200B パラメータモデル
NVIDIA DGX™ Spark は、 AI の構築と実行のためにゼロから設計された新しいクラスのコンピューターです。NVIDIA GB10 Grace Blackwell スーパーチップを搭載し、NVIDIA Grace Blackwell アーキテクチャをベースとする NVIDIA DGX Spark は、最大 1000 TOPS の AI パフォーマンスを実現し、大規模な AI ワークロードを強力にサポートします。128 GB の統合システムメモリにより、開発者は最大 2000 億個のパラメータを持つモデルの実験、微調整、推論を行うことができます。さらに、NVIDIA ConnectX™ ネットワークにより、2 台の NVIDIA DGX Spark スーパーコンピューターを接続することで、最大 4050 億個のパラメータを持つモデルでの推論が可能になります。
開発者に使い慣れたエクスペリエンスを提供するために、NVIDIA DGX Spark は、産業用 AIファクトリーを支えるのと同じソフトウェア アーキテクチャを採用しています。Ubuntu Linux で最新の NVIDIA AI ソフトウェア スタックが事前構成された NVIDIA DGX OS と、NVIDIA NIM™ および NVIDIA Blueprints への開発者プログラム アクセスを使用することで、開発者は Pytorch、Jupyter、Ollama などの一般的なツールを使用して NVIDIA DGX Spark 上でプロトタイプ作成、微調整、推論を行い、データセンターやクラウドにシームレスに展開できます。
NVIDIA DGX Spark はコンパクトなパッケージで圧倒的なパフォーマンスと機能を提供することで、開発者、研究者、データ サイエンティスト、学生が生成 AI の限界を押し広げ続けることを可能にします。
NVIDIA Grace Blackwellをベースに構築
NVIDIA DGX Spark の中核を成すのは、デスクトップ フォーム ファクター向けに最適化された NVIDIA Grace Blackwell アーキテクチャをベースにした新しい NVIDIA GB10 Grace Blackwell スーパーチップです。GB10 は、第 5 世代 Tensor コアと FP4 サポートを備えた強力な NVIDIA Blackwell GPU を搭載し、最大 1000 TOPS の AI コンピューティングを実現します。GB10 は、高性能な Grace 20 コア Arm CPU を搭載し、データの前処理とオーケストレーションを強化し、モデル チューニングとリアルタイム推論を高速化します。GB10 スーパーチップは、NVLink™-C2C を使用することで、PCIe Gen 5 の 5 倍の帯域幅を備えた CPU+GPU コヒーレント メモリ モデルを提供します。
大規模パラメータ AI モデルの操作
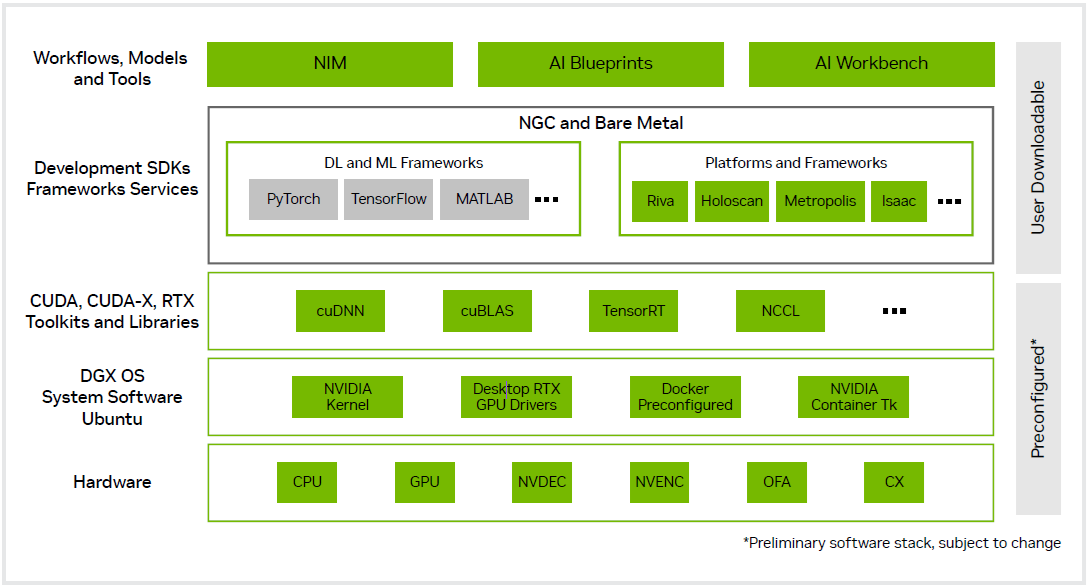
NVIDIA DGX Spark ソフトウェアスタック
128GB の統合システムメモリと FP4 データフォーマットのサポートを備えた NVIDIA DGX Spark は、最大200Bのパラメータを持つ AI モデルをサポートし、AI開発者はデスクトップ上で大規模モデルのプロトタイプ作成、ファインチューニング、推論を行うことができます。NVIDIA ConnectX ネットワークテクノロジを内蔵しているため、2台の NVIDIA DGX Spark システムを接続し、Llama 3.1 405B などのさらに大規模なモデルで作業できます。
ローカルで開発し、大規模にどこにでも展開
NVIDIA DGX Spark は、組織や開発者にプロトタイプモデルのための強力かつ経済的な実験環境を提供し、クラスター環境の貴重なコンピューティングリソースを解放して、実稼働モデルのトレーニングと展開により適した環境を実現します。NVIDIA AI プラットフォームのソフトウェア アーキテクチャを活用することで、NVIDIA DGX Spark ユーザーは、コード変更をほとんど必要とせずに、デスクトップから DGX Cloud や高速クラウド、データセンター インフラストラクチャにモデルをシームレスに移行できるため、プロトタイプの作成、ファインチューニング、反復処理がこれまで以上に容易になります。
3rdロット完売、4thロット手配済み ! 「NVIDIA DGX Spark新春特別キャンペーン」
デスクトップ AI コンピューティングの必要性
生成 AI モデルの規模と複雑さの増大により、ローカルシステムでの開発作業は困難を極めています。大規模モデルのローカルでのプロトタイピング、チューニング、推論には、大量のメモリと高度なコンピューティング性能が必要です。企業、ソフトウェアプロバイダー、政府機関、スタートアップ企業、そして研究者が AI 開発に注力するにつれ、AIコ ンピューティングリソースの必要性は高まり続けています。
デスク上の 200B パラメータモデル
NVIDIA DGX™ Spark は、 AI の構築と実行のためにゼロから設計された新しいクラスのコンピューターです。NVIDIA GB10 Grace Blackwell スーパーチップを搭載し、NVIDIA Grace Blackwell アーキテクチャをベースとする NVIDIA DGX Spark は、最大 1000 TOPS の AI パフォーマンスを実現し、大規模な AI ワークロードを強力にサポートします。128 GB の統合システムメモリにより、開発者は最大 2000 億個のパラメータを持つモデルの実験、微調整、推論を行うことができます。さらに、NVIDIA ConnectX™ ネットワークにより、2 台の NVIDIA DGX Spark スーパーコンピューターを接続することで、最大 4050 億個のパラメータを持つモデルでの推論が可能になります。
開発者に使い慣れたエクスペリエンスを提供するために、NVIDIA DGX Spark は、産業用 AIファクトリーを支えるのと同じソフトウェア アーキテクチャを採用しています。Ubuntu Linux で最新の NVIDIA AI ソフトウェア スタックが事前構成された NVIDIA DGX OS と、NVIDIA NIM™ および NVIDIA Blueprints への開発者プログラム アクセスを使用することで、開発者は Pytorch、Jupyter、Ollama などの一般的なツールを使用して NVIDIA DGX Spark 上でプロトタイプ作成、微調整、推論を行い、データセンターやクラウドにシームレスに展開できます。
NVIDIA DGX Spark はコンパクトなパッケージで圧倒的なパフォーマンスと機能を提供することで、開発者、研究者、データ サイエンティスト、学生が生成 AI の限界を押し広げ続けることを可能にします。
NVIDIA Grace Blackwellをベースに構築
NVIDIA DGX Spark の中核を成すのは、デスクトップ フォーム ファクター向けに最適化された NVIDIA Grace Blackwell アーキテクチャをベースにした新しい NVIDIA GB10 Grace Blackwell スーパーチップです。GB10 は、第 5 世代 Tensor コアと FP4 サポートを備えた強力な NVIDIA Blackwell GPU を搭載し、最大 1000 TOPS の AI コンピューティングを実現します。GB10 は、高性能な Grace 20 コア Arm CPU を搭載し、データの前処理とオーケストレーションを強化し、モデル チューニングとリアルタイム推論を高速化します。GB10 スーパーチップは、NVLink™-C2C を使用することで、PCIe Gen 5 の 5 倍の帯域幅を備えた CPU+GPU コヒーレント メモリ モデルを提供します。
大規模パラメータ AI モデルの操作
NVIDIA DGX Spark ソフトウェアスタック
128GB の統合システムメモリと FP4 データフォーマットのサポートを備えた NVIDIA DGX Spark は、最大200Bのパラメータを持つ AI モデルをサポートし、AI開発者はデスクトップ上で大規模モデルのプロトタイプ作成、ファインチューニング、推論を行うことができます。NVIDIA ConnectX ネットワークテクノロジを内蔵しているため、2台の NVIDIA DGX Spark システムを接続し、Llama 3.1 405B などのさらに大規模なモデルで作業できます。
ローカルで開発し、大規模にどこにでも展開
NVIDIA DGX Spark は、組織や開発者にプロトタイプモデルのための強力かつ経済的な実験環境を提供し、クラスター環境の貴重なコンピューティングリソースを解放して、実稼働モデルのトレーニングと展開により適した環境を実現します。NVIDIA AI プラットフォームのソフトウェア アーキテクチャを活用することで、NVIDIA DGX Spark ユーザーは、コード変更をほとんど必要とせずに、デスクトップから DGX Cloud や高速クラウド、データセンター インフラストラクチャにモデルをシームレスに移行できるため、プロトタイプの作成、ファインチューニング、反復処理がこれまで以上に容易になります。
主な特長
- NVIDIA GB10 Grace Blackwell スーパーチップ搭載
- 第5世代 Tensor Core テクノロジー搭載 NVIDIA Blackwell GPU
- 20コアの高性能 Arm アーキテクチャ搭載 NVIDIA Grace CPU
- FP4 を使用した最大 1000 TOPS の AI パフォーマンス
- 128 GB のコヒーレント統合システムメモリ
- 最大 2,000 億個のパラメータモデルをサポート
- 2 つのシステムをリンクし、最大4,050 億個のパラメータモデルを処理できる NVIDIA ConnectX™ ネットワーク
- 最大 4 TB の NVMe ストレージ
- コンパクトなデスクトップフォームファクター
NVIDIA「DGX Spark」は、パーソナルAIスーパーコンピューターです。Grace Blackwellアーキテクチャを採用し、最大1ペタFLOPSのAI性能と128GBの統合メモリを搭載。クラウドに依存せず、ローカル環境で高度なAI開発を可能にする新しい選択肢として、各業界から注目を集めています。
業界別の活用シーンと期待される用途
主なワークロードとエッジアプリケーション:
業界別の活用シーンと期待される用途
- 医療業界
病院や大学病院では、カルテ作成支援、画像診断、バイタルデータのリアルタイム解析などにDGX Sparkの活用が期待されています。個人情報を外部に出すことなく、院内でAI処理を完結できる点が大きな利点です。 - 教育・研究機関
大学や研究室では、生成AIやVLM(Vision-Language Models)の研究開発、PoC(概念実証)にDGX Sparkの導入が検討されています。学生が実際にAIモデルを動かしながら学べる教育環境としても有用です。 - 製造業
スマートファクトリーやロボティクス開発の現場では、異常検知、品質管理、ロボット制御などにAIを活用するためのローカル環境としてDGX Sparkが注目されています。クラウドに出せない機密データを現場で処理できることが導入の決め手となります。 - 金融業界
信用スコアリングや保険査定などのAI審査モデルの開発において、顧客情報をクラウドに出さずに処理できるDGX Sparkの導入が期待されています。法規制やコンプライアンスへの対応が求められる金融機関にとって、ローカルAI環境は非常に魅力的です。 - 小売・サービス業
顧客行動の分析やチャットボットの開発などにDGX Sparkの活用が検討されています。クラウドコストを抑えつつ、AIによる顧客体験(CX)の向上を図ることができるため、EC企業や店舗運営者にとっても有用な選択肢です。 - スタートアップ・個人開発者
新しいAIモデルのプロトタイピングや検証を高速に行えるほか、最大2台の接続によって、405Bパラメータ規模のモデル(例:Llama 3.1 405B)にも対応可能です。より柔軟な開発環境を構築できます。
主なワークロードとエッジアプリケーション:
- プロトタイピング:AIモデルの設計・検証
- ファインチューニング:最大700億パラメータのモデルに対応
- 推論処理:最大2000億パラメータのモデルをローカルで実行可能
- データサイエンス:NVIDIA RAPIDSによるGPU加速分析
- エッジAI:ロボティクス、コンピュータビジョン、スマートシティ向け開発
このように、DGX Sparkは単体利用だけでなく、小規模クラスタ構成による拡張性も備えており、個人開発者や小規模チームがローカル環境で高度なAIモデルに取り組むための現実的な選択肢となっています。
加えて、DGX Sparkは、シンプルな構成であり、またNVIDIA DGX OSには、最初から様々なツールが組み込まれているため、パッケージから出して、最低限のセットアップですぐに活用できる優れた利便性を備えています。

| 技術仕様 ※ | |
|---|---|
| アーキテクチャ | NVIDIA Grace Blackwell |
| GPU | NVIDIA Blackwell アーキテクチャ |
| CPU | 20 core Arm (10 Cortex-X925 + 10 Cortex-A725 Arm) |
| CUDAコア | NVIDIA Blackwell 世代 |
| Tensorコア | 第5世代 |
| RTコア | 第4世代 |
| Tensor パフォーマンス1 | 1 PFLOP |
| システムメモリ | 128 GB LPDDR5x、統合システムメモリ |
| メモリインターフェイス | 256-bit |
| メモリ帯域幅 | 273 GB/s |
| ストレージ | 自己暗号化機能搭載の 4 TB NVME. M2 |
| USB | 4x USB Type C |
| イーサネット | 1x RJ-45 コネクタ 10 GbE |
| NIC | ConnectX-7 Smart NIC @ 200 Gbps |
| Wi-Fi | WiFi 7 |
| Bluetooth | BT 5.4 w/LE |
| オーディオ出力 | HDMI マルチチャンネル オーディオ出力 |
| 消費電力(システム) | 240 W |
| ディスプレイコネクタ | 1x HDMI 2.1a |
| NVENC | NVDEC | 1x | 1x |
| OS | NVIDIA DGX™ OS |
| システム外形寸法 | 150 mm L x 150 mm W x 50.5 mm H |
| システム重量 | 1.2 kg |
※ 掲載された仕様は現時点におけるものであり、変更される場合があります。
1 スパース演算機能を用いた FP4 TOPS 理論値。
1 スパース演算機能を用いた FP4 TOPS 理論値。
製品同梱物
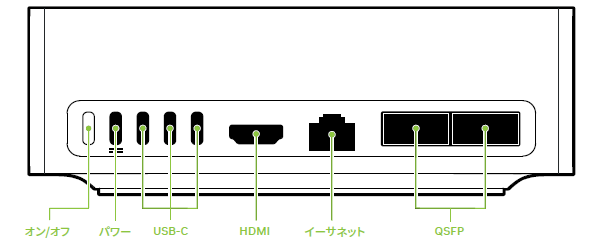
背面パネル
別売オプション
■ DGX Spark 向けケーブル
型番:NJAAKK-N911ーRE
製品:QSFP112 400G DAC CABLE 40cm (DGX Spark間を接続する銅線ケーブルとなります。)
ケーブルイメージ:

補足情報:Connect Two Sparks - Connect two Spark devices and setup them up for inference and fine-tuning
AIコンピューティングの進化:NVIDIA DGX-1からDGX Sparkへ
NVIDIA プレスリリースからの抜粋
| GPUアーキテクチャ | ||
| GPU メモリ | (16GB per GPU) | 統合システムメモリ |
| AI 性能 | ||
| 消費電力 | ||
| システム外形寸法 | ||
| システム重量 |
NVIDIA DGX™ Spark を始めましょう。
NVIDIA プレス・リリース
2026 年 1 月 12 日 NVIDIA BioNeMo Platform Adopted by Life Sciences Leaders to Accelerate AI-Driven Drug Discovery
2025 年 10 月 14 日 NVIDIA DGX Spark が世界の AI 開発者向けに登場
2025 年 06 月 10 日 NVIDIA、2026 年会計年度第 1 四半期の業績を発表
2025 年 05 月 20 日 NVIDIA、世界有数のコンピューター メーカーと協業し、AI に特化した DGX パーソナル コンピューティング システムを発表
2025 年 03 月 20 日 NVIDIA、DGX Spark および DGX Station パーソナル AI コンピューターを発表
2025 年 01 月 08 日 NVIDIA Grace Blackwell がすべてのデスクと AI 開発者のもとへ
NVIDIA ブログ、その他の記事
2026 年 2 月 3 日 Customer Stories : E-Book MediaTek Accelerates AI Development With an AI Factory
2026 年 1 月 13 日 CEOs of NVIDIA and Lilly Share ‘Blueprint for What Is Possible’ in AI and Drug Discovery
2026 年 1 月 07 日 NVIDIA DGX Spark と DGX Station がデスクトップから最新のオープンソースおよび最先端のモデルを駆動
2026 年 1 月 05 日 NVIDIA Rubin Platform, Open Models, Autonomous Driving: NVIDIA Presents Blueprint for the Future at CES
2026 年 1 月 05 日 Quick Start Guide For LTX-2 In ComfyUI
2026 年 1 月 05 日 GeForce @ CES 2026: NVIDIA DLSS 4.5 Announced, 250+ DLSS Multi Frame Generation Games & Apps Available Now, G-SYNC Pulsar Gaming Monitors Available This Week, And Much More
2026 年 1 月 05 日 Open-Source AI Tool Upgrades Speed Up LLM and Diffusion Models on NVIDIA RTX PCs
2026 年 1 月 05 日 New Software and Model Optimizations Supercharge NVIDIA DGX Spark
2026 年 1 月 05 日 NVIDIA RTX Accelerates 4K AI Video Generation on PC With LTX-2 and ComfyUI Upgrades
2026 年 1 月 05 日 NVIDIA DGX Spark and DGX Station Power the Latest Open-Source and Frontier Models From the Desktop
2025 年 12 月 15 日 Inside NVIDIA Nemotron 3: Techniques, Tools, and Data That Make It Efficient and Accurate
2025 年 12 月 15 日 How to Fine-Tune an LLM on NVIDIA GPUs With Unsloth
2025 年 12 月 13 日 Elon Musk Gets Just-Launched NVIDIA DGX Spark: Petaflop AI Supercomputer Lands at SpaceX
2025 年 12 月 03 日 NVIDIA、2026 年会計年度第 3 四半期の業績を発表
2025 年 12 月 02 日 Models Deliver Efficiency, Accuracy at Any Scale
2025 年 11 月 17 日 Accelerated Computing, Networking Drive Supercomputing in Age of AI
2025 年 10 月 29 日 Into the Omniverse: Open World Foundation Models Generate Synthetic Worlds for Physical AI Development
2025 年 10 月 29 日 NVIDIA、AI ネイティブ 6G を加速する Aerial ソフトウェアをオープンソース化
2025 年 10 月 28 日 Powering AI-Native 6G Research with the NVIDIA Sionna Research Kit
2025 年 10 月 28 日 NVIDIA and General Atomics Advance Commercial Fusion Energy
2025 年 10 月 26 日 NVIDIA が 2025 国際ロボット展で講演、数々のパートナーが次世代のロボティクスおよびビジョン AI の潮流を披露
2025 年 10 月 24 日 Open Source AI Week — How Developers and Contributors Are Advancing AI Innovation
2025 年 10 月 24 日 How NVIDIA DGX Spark’s Performance Enables Intensive AI Tasks
2025 年 10 月 23 日 Train an LLM on NVIDIA Blackwell with Unsloth—and Scale for Production
2025 年 10 月 16 日 NVIDIA DGX Spark が世界の AI 開発者向けに登場
2025 年 06 月 10 日 NVIDIA、2026 年会計年度第 1 四半期の業績を発表
2025 年 05 月 21 日 NVIDIA CEO、AI インフラ業界は「数兆ドル規模」と予測
2025 年 05 月 19 日 NVIDIA、COMPUTEX で Best Choice Award を受賞
2025 年 03 月 25 日 GTC 2025 – NVIDIA が今年最大のイベントで、新しいサービスとハードウェア、テクノロジ デモ、AI の今後の展開など、さまざまなニュースを発表
2025 年 03 月 19 日 NVIDIA、ロボット開発を加速させる世界初のヒューマノイド ロボットのオープンな基盤モデル、 Isaac GR00T N1 とシミュレーション フレームワークを発表
ドキュメント
cuSPARSELt v0.8.1 (リンク)
NVIDIA DGX Spark Porting Guide (リンク)
Video Search and Summarization Agent (リンク)
NVIDIA NIM for Large Language Models (LLMs) (リンク)
The NVIDIA Performance Libraries (NVPL) 25.11 (リンク)
CUDA Toolkit 13.1 Release Note (リンク) (PDF)
NVIDIA CUTLASS Documentation (リンク)
NVIDIA Support: Security Bulletin: NVIDIA DGX Spark - November 2025
DGX Sparkについての記載のあるNVIDIAドキュメント
Inference Server
NVIDIA NIM Riva TTS NIM
NVIDIA NIM for Visual Generative AI (GenAI)
NVIDIA Nsight Systems Analysis guide - Post-Collection Analysis Guide (リンク)
Video Search and Summarization Agent - VSS Event Reviewer (リンク)
NVIDIA Holoscan SDK v3.8.0 (リンク)
DeepStream SDK 8.0 for NVIDIA dGPU/X86 and Jetson (リンク)
NVIDIA GPU Operator - Supported ARM Based Platforms (リンク)
NVIDIA cuDSS (リンク)
Cosmos-Predict2 (リンク)
NVIDIA Optimized Frameworks - vLLM Release 25.09 / 25.10 / 25.11 (リンク)
Holoscan Sensor Bridge v2.5.0-EA (リンク)
TensorRT Documentation - Support Matrix (リンク)
プレゼンテーション
Oct25 - Accelerate Research and Learning with DGX Spark (NVIDIA On-Demandより)
GTC25 - DGX Spark: Your Personal AI Supercomputer (NVIDIA On-Demandより)
NVIDIA GTC AI カンファレンス 2026 でDGX Sparkに関連するであろうセッションのご案内
Hands-On NVIDIA DGX Spark 【DLIT82308】
Best Practices for Accelerating LLM and VLM Inference With vLLM 【CWES82007】
Boost Data Science Pipelines With Accelerated Libraries 【CWES82212】
DGX Spark / GB10 User Forum
DGX Spark / GB10 FAQ
User Forumより抜粋
Home->Accelerated Computing->DGX Spark / GB10 User Forum->Announcements:
DGX Spark Software Updates
Home->Accelerated Computing->DGX Spark / GB10 User Forum->DGX Spark / GB10:
DGX Spark / GB10 FAQ
Reviews are coming in
NVIDIA Developer Webinar
日付: 2026年 2月12日(木)
開始時間:日本時間 午後2時30分~ (11:00 a.m. IST | 1:30 p.m. SGT )
長さ: 1 時間
タイトル: Getting Started with NVIDIA DGX Spark: The Personal AI Supercomputer
要事前登録:Webinar登録ページ
YouTube動画
〇 NVIDIA -
2026年 1 月 16 日 更新: GDX Platform (プレイリスト)
2026年 1 月 07 日: NVIDIA DGX Spark で Hugging Face を使って独自の AI アシスタントを構築する
2026年 1 月 05 日: CES 2026 - NVIDIA Live with CEO Jensen Huang
2025 年 10 月 17 日 : DGX SparkがSpaceXに登場: ジェンセン・フアンとイーロン・マスクがAIの未来を始動
2025 年 10 月 16 日 : 大きな何かを起こす:NVIDIA DGX Spark が登場
2025 年 9 月 18 日 : タンパク質AIを加速するパーソナルAIスーパーコンピュータ
2025 年 3 月 19 日 : NVIDIA GTC Spring 2025 基調講演: NVIDIA DGX Spark の紹介
2025 年 1 月 09 日 : NVIDIA DGX Spark | A Grace Blackwell AI Supercomputer on your desk
〇 NVIDIA Developer -
2026 年 2 月 08 日 更新 : NVIDIA DGX Spark Livestreams (プレイリスト)
2026 年 2 月 02 日 更新 : NVIDIA DGX Spark Demos (プレイリスト)
2026 年 2 月 07 日 : DGX Spark Live: Your Questions Answered Vol. 2
2026 年 1 月 31 日 : DGX Spark Live: Rapid AI Agent Development
2026 年 1 月 24 日 : DGX Spark Live: Sovereign Data Solutions on DGX Spark with GT Edge AI
2026 年 1 月 16 日 : DGX Spark Lights Up the Show Floor at CES
2026 年 1 月 15 日 : NVIDIA DGX Spark Lights up CES 2026 Show Floor
2026 年 1 月 14 日 : Agentic AI Solutions with CrewAI and Nemotron | Nemotron Labs
2026 年 1 月 10 日 : CES meets DGX Spark 2026 wrap-up
2025 年 12 月 20 日 : DGX Spark Live: Real-Time Worker Safety with OnSight AI, Powered by DGX Spark and Smart Glasses
2025 年 12 月 13 日 : DGX Spark Live: Installation & First Run Guide for Robotics Developers
2025 年 12 月 12 日 : Getting Started with Edge AI on NVIDIA Jetson: LLMs, VLMs, and Foundation Models for Robotics
2025 年 12 月 10 日 : For the Innovator Who Has Everything (Except This) ... an NVIDIA DGX Spark
2025 年 12 月 06 日 : DGX Spark Live: Backend Development with Local LLM Inference
2025 年 11 月 22 日 : DGX Spark Live: Process Text for GraphRAG With Up to 120B LLM
2025 年 11 月 15 日 : DGX Spark: Powering EPRI’s AI Research
2025 年 11 月 05 日 : Build Specialized AI Agents: Post-GTC Developer Deep Dive
2025 年 11 月 01 日 : DGX Spark: 光速で宇宙を観測する
2025 年 10 月 31 日 : Surprising the Golden Ticket Winners with DGX Sparks at #NVIDIAGTC
2025 年 10 月 28 日 : Turn Text Into a Knowledge Graph with 70B LLM on DGX Spark
2025 年 10 月 28 日 : DGX Spark の 70B LLM を使用してテキストをナレッジ グラフに変換
2025 年 10 月 25 日 : DGX Spark Live: Developer Q&A
2025 年 10 月 24 日 : DGX Spark: Accelerated cuPyNumeric on your Desktop Cluster
2025 年 10 月 24 日 : Developer Insights | NVIDIA DGX Spark at PyTorch Conference
2025 年 10 月 15 日 : NVIDIA DGX Spark を使い始める
2025 年 10 月 11 日 : DGX Spark でマルチエージェント チャットボットのデモを構築する
2025 年 10 月 11 日 : How to Take Advantage of NVIDIA DGX Spark? Experiment.
2025 年 10 月 08 日 : DGX Spark での Vibe コーディング デモ
2025 年 9 月 19 日 : Where can I rent the most cost-effective #GPU infra? | #nvidia
2025 年 8 月 30 日 : NVIDIA DGX Spark を使用した 8B パラメータ モデルのローカルでの微調整のデモ
2025 年 5 月 24 日 : Jensen Huang Shows Off the New #NVIDIA DGX Spark Personal AI Computer
〇 NVIDIA Omniverse
2026 年 1 月 29 日 : Simulation to Real Robotics with Isaac Sim and Isaac Lab: Community Showcase
2025 年 5 月 24 日 : Newton's Classroom - The Physics Class Every Robot Should Attend
〇 NVIDIA GTC
2025 ハイライト (PDF)
- DGX Spark / GB10 での構築を開始
-
NVIDIA デベロッパーサイト、フォーラム (要ログイン)
NVIDIA プレス・リリース
2026 年 1 月 12 日 NVIDIA BioNeMo Platform Adopted by Life Sciences Leaders to Accelerate AI-Driven Drug Discovery
2025 年 10 月 14 日 NVIDIA DGX Spark が世界の AI 開発者向けに登場
2025 年 06 月 10 日 NVIDIA、2026 年会計年度第 1 四半期の業績を発表
2025 年 05 月 20 日 NVIDIA、世界有数のコンピューター メーカーと協業し、AI に特化した DGX パーソナル コンピューティング システムを発表
2025 年 03 月 20 日 NVIDIA、DGX Spark および DGX Station パーソナル AI コンピューターを発表
2025 年 01 月 08 日 NVIDIA Grace Blackwell がすべてのデスクと AI 開発者のもとへ
NVIDIA ブログ、その他の記事
2026 年 2 月 3 日 Customer Stories : E-Book MediaTek Accelerates AI Development With an AI Factory
2026 年 1 月 13 日 CEOs of NVIDIA and Lilly Share ‘Blueprint for What Is Possible’ in AI and Drug Discovery
2026 年 1 月 07 日 NVIDIA DGX Spark と DGX Station がデスクトップから最新のオープンソースおよび最先端のモデルを駆動
2026 年 1 月 05 日 NVIDIA Rubin Platform, Open Models, Autonomous Driving: NVIDIA Presents Blueprint for the Future at CES
2026 年 1 月 05 日 Quick Start Guide For LTX-2 In ComfyUI
2026 年 1 月 05 日 GeForce @ CES 2026: NVIDIA DLSS 4.5 Announced, 250+ DLSS Multi Frame Generation Games & Apps Available Now, G-SYNC Pulsar Gaming Monitors Available This Week, And Much More
2026 年 1 月 05 日 Open-Source AI Tool Upgrades Speed Up LLM and Diffusion Models on NVIDIA RTX PCs
2026 年 1 月 05 日 New Software and Model Optimizations Supercharge NVIDIA DGX Spark
2026 年 1 月 05 日 NVIDIA RTX Accelerates 4K AI Video Generation on PC With LTX-2 and ComfyUI Upgrades
2026 年 1 月 05 日 NVIDIA DGX Spark and DGX Station Power the Latest Open-Source and Frontier Models From the Desktop
2025 年 12 月 15 日 Inside NVIDIA Nemotron 3: Techniques, Tools, and Data That Make It Efficient and Accurate
2025 年 12 月 15 日 How to Fine-Tune an LLM on NVIDIA GPUs With Unsloth
2025 年 12 月 13 日 Elon Musk Gets Just-Launched NVIDIA DGX Spark: Petaflop AI Supercomputer Lands at SpaceX
2025 年 12 月 03 日 NVIDIA、2026 年会計年度第 3 四半期の業績を発表
2025 年 12 月 02 日 Models Deliver Efficiency, Accuracy at Any Scale
2025 年 11 月 17 日 Accelerated Computing, Networking Drive Supercomputing in Age of AI
2025 年 10 月 29 日 Into the Omniverse: Open World Foundation Models Generate Synthetic Worlds for Physical AI Development
2025 年 10 月 29 日 NVIDIA、AI ネイティブ 6G を加速する Aerial ソフトウェアをオープンソース化
2025 年 10 月 28 日 Powering AI-Native 6G Research with the NVIDIA Sionna Research Kit
2025 年 10 月 28 日 NVIDIA and General Atomics Advance Commercial Fusion Energy
2025 年 10 月 26 日 NVIDIA が 2025 国際ロボット展で講演、数々のパートナーが次世代のロボティクスおよびビジョン AI の潮流を披露
2025 年 10 月 24 日 Open Source AI Week — How Developers and Contributors Are Advancing AI Innovation
2025 年 10 月 24 日 How NVIDIA DGX Spark’s Performance Enables Intensive AI Tasks
2025 年 10 月 23 日 Train an LLM on NVIDIA Blackwell with Unsloth—and Scale for Production
2025 年 10 月 16 日 NVIDIA DGX Spark が世界の AI 開発者向けに登場
2025 年 06 月 10 日 NVIDIA、2026 年会計年度第 1 四半期の業績を発表
2025 年 05 月 21 日 NVIDIA CEO、AI インフラ業界は「数兆ドル規模」と予測
2025 年 05 月 19 日 NVIDIA、COMPUTEX で Best Choice Award を受賞
2025 年 03 月 25 日 GTC 2025 – NVIDIA が今年最大のイベントで、新しいサービスとハードウェア、テクノロジ デモ、AI の今後の展開など、さまざまなニュースを発表
2025 年 03 月 19 日 NVIDIA、ロボット開発を加速させる世界初のヒューマノイド ロボットのオープンな基盤モデル、 Isaac GR00T N1 とシミュレーション フレームワークを発表
ドキュメント
cuSPARSELt v0.8.1 (リンク)
NVIDIA DGX Spark Porting Guide (リンク)
Video Search and Summarization Agent (リンク)
NVIDIA NIM for Large Language Models (LLMs) (リンク)
The NVIDIA Performance Libraries (NVPL) 25.11 (リンク)
CUDA Toolkit 13.1 Release Note (リンク) (PDF)
NVIDIA CUTLASS Documentation (リンク)
NVIDIA Support: Security Bulletin: NVIDIA DGX Spark - November 2025
DGX Sparkについての記載のあるNVIDIAドキュメント
Inference Server
NVIDIA NIM Riva TTS NIM
NVIDIA NIM for Visual Generative AI (GenAI)
NVIDIA Nsight Systems Analysis guide - Post-Collection Analysis Guide (リンク)
Video Search and Summarization Agent - VSS Event Reviewer (リンク)
NVIDIA Holoscan SDK v3.8.0 (リンク)
DeepStream SDK 8.0 for NVIDIA dGPU/X86 and Jetson (リンク)
NVIDIA GPU Operator - Supported ARM Based Platforms (リンク)
NVIDIA cuDSS (リンク)
Cosmos-Predict2 (リンク)
NVIDIA Optimized Frameworks - vLLM Release 25.09 / 25.10 / 25.11 (リンク)
Holoscan Sensor Bridge v2.5.0-EA (リンク)
TensorRT Documentation - Support Matrix (リンク)
プレゼンテーション
Oct25 - Accelerate Research and Learning with DGX Spark (NVIDIA On-Demandより)
GTC25 - DGX Spark: Your Personal AI Supercomputer (NVIDIA On-Demandより)
NVIDIA GTC AI カンファレンス 2026 でDGX Sparkに関連するであろうセッションのご案内
Hands-On NVIDIA DGX Spark 【DLIT82308】
Best Practices for Accelerating LLM and VLM Inference With vLLM 【CWES82007】
Boost Data Science Pipelines With Accelerated Libraries 【CWES82212】
※ 各セッションの詳細は上記リンクをクリックし、ご確認ください。
NVIDIA GTC AIカンファレンス 2026は、現地及びバーチャル(オンライン)の両開催となります。
現地での参加登録費用は、こちらを参照ください。
また、バーチャルでは、無料で参加登録することが出来ます。登録するには、各ページ右上に表示されている
「今すぐ登録|ログイン」ボタンをクリックし、必ず「Virtual」を選択し登録にお進みください。
DGX Spark / GB10 User Forum
DGX Spark / GB10 FAQ
User Forumより抜粋
Home->Accelerated Computing->DGX Spark / GB10 User Forum->Announcements:
DGX Spark Software Updates
Home->Accelerated Computing->DGX Spark / GB10 User Forum->DGX Spark / GB10:
DGX Spark / GB10 FAQ
Reviews are coming in
NVIDIA Developer Webinar
日付: 2026年 2月12日(木)
開始時間:日本時間 午後2時30分~ (11:00 a.m. IST | 1:30 p.m. SGT )
長さ: 1 時間
タイトル: Getting Started with NVIDIA DGX Spark: The Personal AI Supercomputer
要事前登録:Webinar登録ページ
YouTube動画
〇 NVIDIA -
2026年 1 月 16 日 更新: GDX Platform (プレイリスト)
2026年 1 月 07 日: NVIDIA DGX Spark で Hugging Face を使って独自の AI アシスタントを構築する
2026年 1 月 05 日: CES 2026 - NVIDIA Live with CEO Jensen Huang
2025 年 10 月 17 日 : DGX SparkがSpaceXに登場: ジェンセン・フアンとイーロン・マスクがAIの未来を始動
2025 年 10 月 16 日 : 大きな何かを起こす:NVIDIA DGX Spark が登場
2025 年 9 月 18 日 : タンパク質AIを加速するパーソナルAIスーパーコンピュータ
2025 年 3 月 19 日 : NVIDIA GTC Spring 2025 基調講演: NVIDIA DGX Spark の紹介
2025 年 1 月 09 日 : NVIDIA DGX Spark | A Grace Blackwell AI Supercomputer on your desk
〇 NVIDIA Developer -
2026 年 2 月 08 日 更新 : NVIDIA DGX Spark Livestreams (プレイリスト)
2026 年 2 月 02 日 更新 : NVIDIA DGX Spark Demos (プレイリスト)
2026 年 2 月 07 日 : DGX Spark Live: Your Questions Answered Vol. 2
2026 年 1 月 31 日 : DGX Spark Live: Rapid AI Agent Development
2026 年 1 月 24 日 : DGX Spark Live: Sovereign Data Solutions on DGX Spark with GT Edge AI
2026 年 1 月 16 日 : DGX Spark Lights Up the Show Floor at CES
2026 年 1 月 15 日 : NVIDIA DGX Spark Lights up CES 2026 Show Floor
2026 年 1 月 14 日 : Agentic AI Solutions with CrewAI and Nemotron | Nemotron Labs
2026 年 1 月 10 日 : CES meets DGX Spark 2026 wrap-up
2025 年 12 月 20 日 : DGX Spark Live: Real-Time Worker Safety with OnSight AI, Powered by DGX Spark and Smart Glasses
2025 年 12 月 13 日 : DGX Spark Live: Installation & First Run Guide for Robotics Developers
2025 年 12 月 12 日 : Getting Started with Edge AI on NVIDIA Jetson: LLMs, VLMs, and Foundation Models for Robotics
2025 年 12 月 10 日 : For the Innovator Who Has Everything (Except This) ... an NVIDIA DGX Spark
2025 年 12 月 06 日 : DGX Spark Live: Backend Development with Local LLM Inference
2025 年 11 月 22 日 : DGX Spark Live: Process Text for GraphRAG With Up to 120B LLM
2025 年 11 月 15 日 : DGX Spark: Powering EPRI’s AI Research
2025 年 11 月 05 日 : Build Specialized AI Agents: Post-GTC Developer Deep Dive
2025 年 11 月 01 日 : DGX Spark: 光速で宇宙を観測する
2025 年 10 月 31 日 : Surprising the Golden Ticket Winners with DGX Sparks at #NVIDIAGTC
2025 年 10 月 28 日 : Turn Text Into a Knowledge Graph with 70B LLM on DGX Spark
2025 年 10 月 28 日 : DGX Spark の 70B LLM を使用してテキストをナレッジ グラフに変換
2025 年 10 月 25 日 : DGX Spark Live: Developer Q&A
2025 年 10 月 24 日 : DGX Spark: Accelerated cuPyNumeric on your Desktop Cluster
2025 年 10 月 24 日 : Developer Insights | NVIDIA DGX Spark at PyTorch Conference
2025 年 10 月 15 日 : NVIDIA DGX Spark を使い始める
2025 年 10 月 11 日 : DGX Spark でマルチエージェント チャットボットのデモを構築する
2025 年 10 月 11 日 : How to Take Advantage of NVIDIA DGX Spark? Experiment.
2025 年 10 月 08 日 : DGX Spark での Vibe コーディング デモ
2025 年 9 月 19 日 : Where can I rent the most cost-effective #GPU infra? | #nvidia
2025 年 8 月 30 日 : NVIDIA DGX Spark を使用した 8B パラメータ モデルのローカルでの微調整のデモ
2025 年 5 月 24 日 : Jensen Huang Shows Off the New #NVIDIA DGX Spark Personal AI Computer
〇 NVIDIA Omniverse
2026 年 1 月 29 日 : Simulation to Real Robotics with Isaac Sim and Isaac Lab: Community Showcase
2025 年 5 月 24 日 : Newton's Classroom - The Physics Class Every Robot Should Attend
〇 NVIDIA GTC
2025 ハイライト (PDF)