LIQID CDIのサーバーとGPUの接続柔軟性・拡張性について

前回は、LIQID社のコンポーザブル・ディスアグリゲーテッド・インフラストラクチャー(CDI)について紹介致しました。今回は、そのCDIがどのような用途で使用されたのか、ユースケースの1つとして、O社の例をご紹介致します。
O社は、PCIeファブリックスイッチを介して接続されているPCIeデバイス(GPU, SSD, NICなど)を、Liqid社のソフトウェア(Liqid Matrix Software)で柔軟にシームレスに接続し利用できる、というCDIの特徴をAI用途に活用致しました。
用意されたCDIのシステムとしては、以下のような構成をイメージして頂けます。
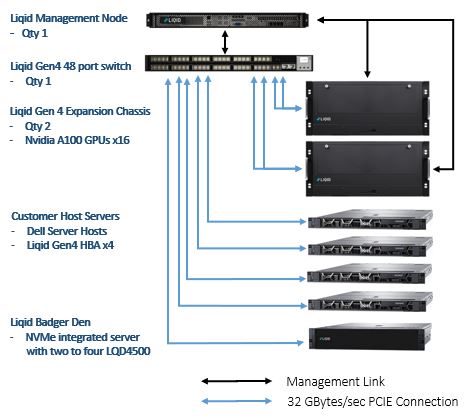
上から順番に以下の内容で構成されています。
・Liqid Management Node : Liqid Matrix SoftwareがインストールされているDirectorになります。
・Liqid Gen4 48 port switch : Liqid PCIe ファブリックスイッチです。このスイッチ経由で全てのPCIeデバ
イスが接続され、Liqid Matrix SoftwareによりPCIeデバイスの構成/解放の管理が実施されます。
・Liqid Gen4 Expansion Chassis : PCIeデバイス(GPU, SSD, NIC等)がこの拡張シャーシに実装され、PCIe
ファブリックスイッチ経由で接続されます。
・Customer Host Servers : お客様が用意されるサーバーです。サーバーにLiqid Gen4 HBAをインストールし
PCIeファブリックスイッチと接続する事により、Liqid Matrix SoftwareによってPCIeデバイスと接続されます。
・Liqid Badger Den : NVMe Integrated Serverで、LQD4500( 6.40, 7.68, 12.80, 15.36, 25.60 and 30.72TB )を実装します。
この用意されたCDIシステムから、実行したい環境の構成を、Liqid Matrix SoftwareでプールされているPCIeデバイスをサーバーに割当て、1つのファブリックを構成します。
Liqid Gen4 Expansion ChassisにはPCIeスロットが8スロット製品(EX-4408)と10スロット製品(EX-4410)の2種類があります。GPUを16基ご用意される際には、各EX-4408に8基のGPUをインストールして、2台のEX-4408に実装という構成もご検討頂けます。ご使用の際に、どのサーバーに、どのGPUを何基割り当てるかは、Directorにイーサネットで接続されている操作用PCのブラウザから、DirectorのLiqid Matrix Softwareにログインし、そのブラウザからのGUI操作でサーバー及びPCIeデバイス(この例ではGPU)をPCIeファブリックスイッチ経由で構成または解除し、ご使用ごとにその構成を再構成して頂けます。もしこのCDIがなければ、GPUを何基使用するか変更する際、もしくは他のサーバーで使用したGPUを使用したい際、GPUの数によってはサーバーの電源を落として、物理的にPCIeバスからGPUを抜き差しする作業等が想定されますし、使用するサーバーのPCIeスロット数によるPCIeデバイス数の制限が出てきます。しかしO社はこのCDIの特徴を活用し、1台のサーバーで、GPUの使用数を、1基、2基、4基、8基そして16基と、Liqid Matrix Softwareによって、GPU数の割り当てを再構成で変更しました。
このLiqid CDIの特徴を生かし、O社のData&AIチームとLiqidは、自然言語処理(Natural Language Processing : NPL)トレーニングのために、用意されたシステムから、LIQID Matrix Softwareで以下のように構成しました。
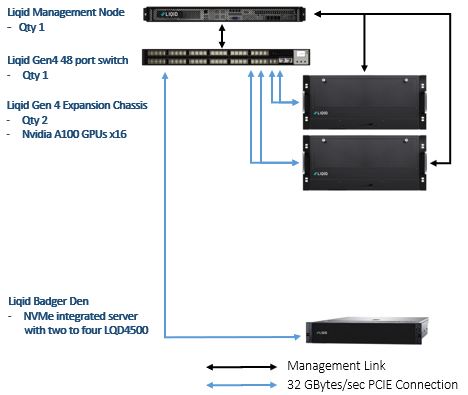
ホストサーバーとしては1台、Liqid Badger Denが使用されました。このLiqid Badger Den は、LQD4500が実装されたDell PowerEdge R7525(AMD 7H12 64 Core)で構成されていますので、ホストサーバーとして活用されました。またこのR7525に実装されたLQD4500(16TB NVMe)はDeep Learningのキャッシュに使用されました。2台のLiqid Gen4 Expansion Chassisに実装されている16基のNVIDIA A100 GPUを全てLiqid Matrix SoftwareでPCIeファブリックスイッチ経由でこのR7525に接続し、AI処理が行われました。
GPU数によるpyTorch NPL 処理時間の比較としては、GPUの使用数が、1基、2基、4基、8基そして16基にて1つのサーバーに割当てを再構成しながら比較し、GPU1基使用時には、約73K Token/Sec、しかしGPUを16基の際には、800K Token/Secとなり、プールされているリソース(この場合はGPU)を有効活用する事により、より時間当たりの処理が向上した事が示されています。
このように、使用するサーバーにおけるPCIeデバイスを、動的に再構成して使用頂ける事から、CDIにより、よりリソースの効率化を図れる事が示されているかと思われます。このCDIがどのような構成で、どのように再構成が行われるか、分かり易いLiqid社のYoutubeがありますので、是非ご覧ください。