LIQID ブログ:なぜCXLはインメモリデータベースのゲームチェンジャーになるのか?

(以下はLIQID社ホームページに掲載されたブログの弊社和訳です:Why CXL Will Change the Game for In-Memory Databases)
システム技術者として、私はキャリアの大半を優秀なデータベースチームが「メモリ」というシンプルだが厄介な問題と格闘する姿を見て過ごしてきました。インメモリデータベース(IMDB)は、ディスクのレイテンシを排除することで劇的な性能向上を目指しましたが、DRAMのコストと容量上限という厳しい制約にずっと縛られてきました。
ここ10年の回避策は「シャーディング」でした。データベースを分割し多数のサーバーに分散させる方法です。確かに、これは機能しましたがその代償も大きかったのです。シャードが増えるたびにレイテンシが増加し冗長性が膨れ上がり、運用の負荷も増加しました。クエリ遅延が増加し、レプリカが増殖し、運用チームはリバランスやフェイルオーバーの管理で多くの時間を消費してきました。
Compute Express Link(CXL)はこの構図を完全に変えることができます。CXLにより、マザーボードのメモリスロットに搭載できる容量を超えてメモリを拡張・プールでき、ノードあたり数TBから数百TBの規模にまで拡大できます。これにより、IMDBが元々掲げていた「理論上の」性能向上が、実際に達成可能なものになるのです。
なぜこれがあなた——データベースアーキテクトやデータサイエンティスト——にとって重要なのか、そして今後数年でCXLがあなたのシステム基盤をどのように変えていくのか、説明させてください。
シャーディングは戦略ではなく“税金”だった
私たちはシャーディングを「スケールする唯一の方法」として受け入れてきましたが、実際にはそれは“税金”のようなものでした。
- レイテンシのペナルティ:シャードが増えると、シャードごとにクエリレイテンシが10〜30%増加。単一ノードで10msのクエリが、100ms以上に膨れ上がることもあります。
- レプリケーションの負荷:メタデータやホットデータセットをノード間で複製する必要があり、メモリと帯域を消費します。
- 運用の複雑化:リシャーディング、負荷分散、障害復旧が複雑さを増し、価値創出よりも保守作業に時間を取られます。
CXLでは、この“税金”が無くなります。例えば20TBの金融リスク分析ワークロードも、5台のサーバーにシャーディングする代わりに、2TB DRAM + 18TBのCXLメモリを搭載した1台のノードで処理できます。LIQID製品のようなコンポーザブル・ディスアグリゲーション型CXLシャーシを使えば1ノードで50TB、100TBのメモリを持つことも可能です。
あなた——アーキテクト——にとっても、これは設計がシンプルになり、構成要素が減り、レイテンシが劇的に低減することを意味します。
本当の意味でのティアードメモリアーキテクチャ
現実には、多くのデータは“ホット”ではありません。20%のデータが80%のアクセスを占めるというパレート分布を見ているはずです。しかしこれまでは、DRAMとSSDの中間がありませんでした。高価なDRAMか、SSDの(数十マイクロ秒〜ミリ秒という)高遅延かのどちらかしかなかったのです。
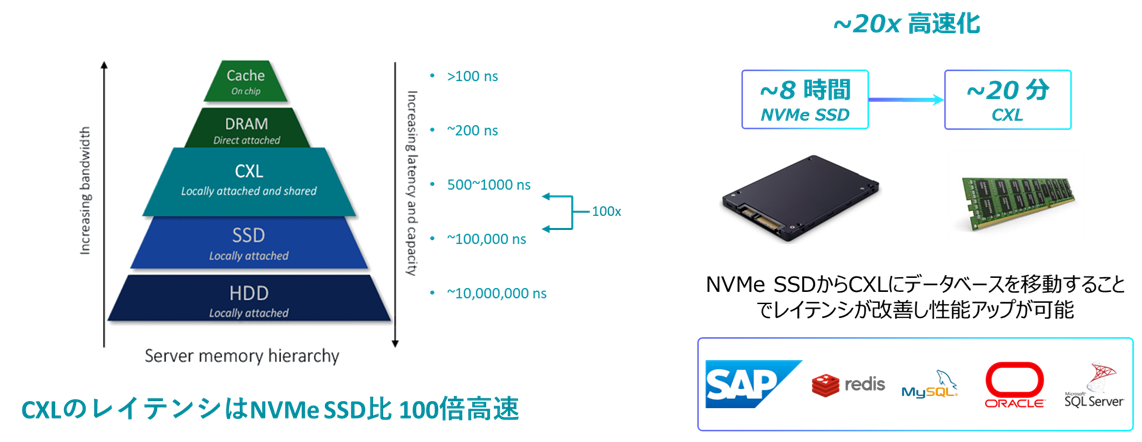
CXLは新たな第3のメモリ階層を提供します:
- ホットデータ:DRAM(80〜120ns、〜200GB/s/ソケット)
- ウォーム/コールドデータ:CXL.mem(200〜800ns、最大256GB/s/ノード)
- アーカイブ:SSD(50〜100µs、GB/s)
これにより、ホットはDRAM、ロングテールはCXLに置きつつ、ディスクに落とさず全データをメモリ上に収めることが可能になります。
データサイエンティストには、学習データや特徴量ストア、グラフ構造がクエリ中にSSDへスピルしないという利点があります。アーキテクトには、ワークロード全体で予測可能な性能が得られます。
データベースとAIの融合
CXLのもっともエキサイティングな側面の1つは、データベースとAIの境界が消え始めていることです。
いくつか具体例を挙げます:
ベクターデータベース(Milvus, Pinecone)
DRAMにIVFインデックス、CXL.memにパーティションを配置すれば、単一ノードで40〜100TBの埋め込みデータを保持可能。
レイテンシは100ms(シャーディング時)から約10msへ。
グラフデータベース
数十億ノードの不正検知グラフもSSDにスピルしない。
ホットな不正リングはDRAM、ロングテールはCXL.memに格納。
これまで秒単位かかった処理が1ms以下に。
ハイブリッド OLTP + AI
推薦システムのナレッジベースや埋め込み推論を**同じメモリプールで実行**でき、PCIeコピーも重複データも不要。
I/Oボトルネックなき分析処理へ
TPC-H 風の分析ワークロードを考えてみましょう:
- SSDで1TBテーブルをスキャン → 約30秒
- CXL.memで同じスキャン → 約3秒
- DRAM → 約2秒
これは漸進的改善ではなく、**桁違いの改善**であり、ボトルネックがI/OからCPUに移ることを意味します。
永続CXLの未来
第一世代のCXLデバイスは拡張が主用途ですが、**永続化**はすぐそこです。
IMDBのチェックポイントを永続CXLへ直接書き込めれば:
SSDログ不要
数分かかったリカバリが数秒に短縮
金融リスク、不正検知、トレーディングなど、復旧時間が極めて重要な領域では特に大きな意味を持ちます。
なぜ「今」重要なのか
誇張と現実を見分けねばならない技術リーダーにとって、これは明確に「現実」です。あらゆるCPU、GPU、メモリベンダーがCXLを中心に設計しており、ハイパースケーラーはすでに大規模運用中です。
戦略的含意はすぐに訪れます:
- スケールアップを再考せよ:10TB〜100TB級の単一ノードIMDBが現実に。
- スタックを統合せよ:DBとAIの分離は不要に。
- TCOを見直せ:シャーディングはコスト増。CXL集中型ノードは運用とハード両方を削減。
- 永続化に備えよ:CXLがメモリとストレージの境界を溶かす。
結び
インメモリデータベースは常に究極の性能を約束してきましたが、DRAMがその限界でした。私たちはシャーディングでその延命を図りましたが、レイテンシと複雑さが代償でした。
CXLはその境界を取り払います。
1ノードで50TB、100TB以上のIMDB。
AIとDBが一つのメモリファブリックで統合。
運用負荷ではなく、イノベーションへ集中できる世界。
メモリ分離(Disaggregation)の時代はすでに始まっており、IMDBはCXLの“キラーアプリ”になるでしょう。
残る唯一の問いは、「どれほど早くこれを採用するか」です。