In-Network Computing – メラノックスの提唱する新たなコンピューティングの形
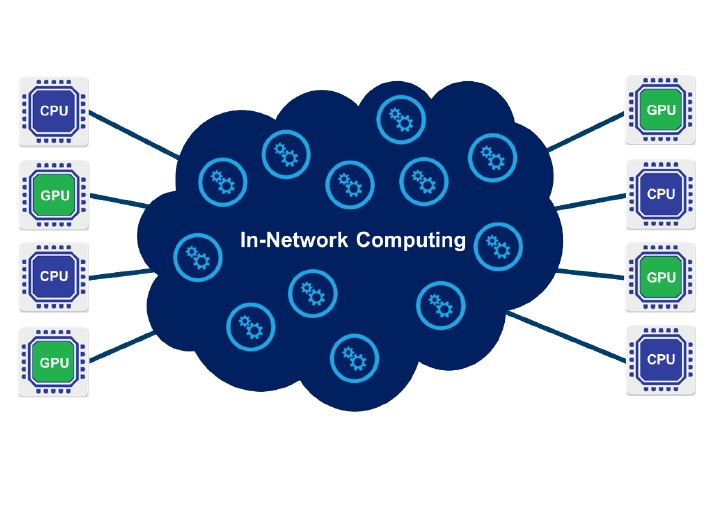
メラノックスでは、現在、ハイパフォーマンスコンピューティング(HPC)市場に向けて、新たなコンピューティングの形として、「In-Network Computing」を推し進めています。従来の 「CPUセントリック」のコンピューティングでは、(アプリケーション、OSカーネル、フレームワーク)全ての処理をCPUがソフトウェアで実行しているのに対し、メラノックスの提唱するデータセントリックなコンピューティングでは、CPUだけでなく、カード、スイッチなどのファブリックを含めたネットワークのあらゆる部分で(事前処理、リアルタイム処理、カーネルのオフロードなどの)演算が実行される形となります。例えば、ストレージ内やネットワークでのデータ移動時にも処理を行うことで、スケーラビリティと性能を同時に向上させるものになります。
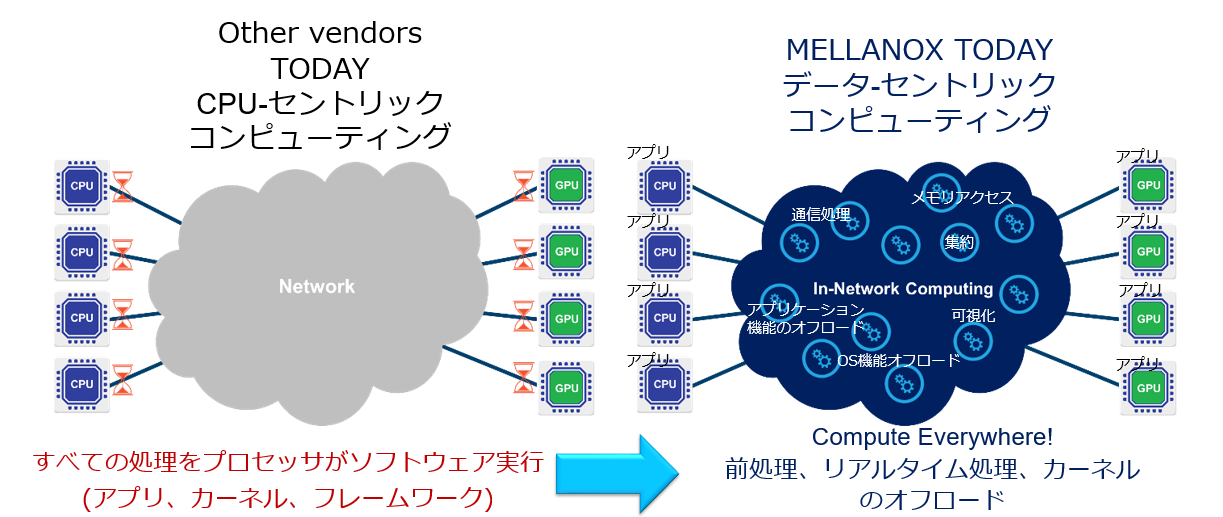
一方、上記左側の「CPU-セントリック」なコンピューティングでは、例えばデータ転送自体についてもCPUリソースを活用する形となります。CPUですべてをカバーし積極的に活用することを念頭に置けばハードウェアの設計自体を比較的簡素にすることが可能となり、(カードが使用するCPUリソースをファブリックの費用に換算しなければ)コスト面では有利にみえますが、その一方で、100Gb/sなどデータ転送レートが大きくなればなるほど、また接続するノードの数が増えれば増えるほど、単位時間あたりに転送するべきデータ量が増大し、それを処理するためにCPUのリソースが圧迫されることになります。本来演算に使われるべきCPUリソースが、演算ではなくデータ転送を処理するために活用されることになるのです。
これに対し、メラノックスのデータ・セントリックコンピューティングでは、RDMA転送によりデータ転送自体にCPUリソースを使用しないことに加え、スイッチ上のSHArP(Scalable Hierarchical Aggregation and Reduction Protocol)™機能によるMPI通信の最適化や、カードに搭載するMPI Tag-Matchingオフロードをはじめとする各種のオフロードエンジンにより、CPUが演算に投入できるリソースを拡大するとともに、ファブリックのスケーラビリティを確保するものになります。
ある意味アプローチの違いとして、有り余るCPUリソースを存分に活用するという考え方なのか、限られたCPUリソースをより有効に活用するという考え方なのかを示したものではあるのですが、HPC市場では、どちらの選択がより重要なのかを考えていただくとよいのかもしれません。
GPGPU搭載システムが一般的になってきている今、何故引き続き高性能なCPUを搭載したサーバーをお求めになるのでしょうか…
